Digitalisierung und Volltexterkennung der ehemals Reichenauer Inkunabeln
Katharina Ost 13.10.2023 15.45 Uhr
DOI: https://doi.org/10.58019/mfc6-5w30
Katharina Ost ist Projektmitarbeiterin an der Badischen Landesbibliothek und arbeitet in einem Projekt zu den Reichenauer Inkunabeln. In diesem Projekt, das von der Stiftung Kulturgut Baden-Württemberg gefördert wird, werden die in der Badischen Landesbibliothek befindlichen Inkunabeln Reichenauer Provenienz digitalisiert und mit qualitativ verbesserten Metadaten online verfügbar gemacht.Was dabei genau ihre Aufgaben sind, erfahren Sie in diesem Interview.
Worum geht es in dem Projekt?
Unser Projekt macht eine über 200 Titel umfassende Sammlung sogenannter Wiegendrucke aus der ehemaligen Bibliothek des Klosters Reichenau erstmals digital zugänglich. Der Bestand der Reichenauer Klosterbibliothek, dem auch zahlreiche mittelalterliche Handschriften angehören, gelangte 1804 im Zuge der Säkularisation an die damalige großherzoglich-badische Hofbibliothek in Karlsruhe. Im Vergleich zu den Handschriften wurden seine Wiegendrucke seither jedoch eher wenig erforscht. Dabei lassen zahlreiche handschriftliche Eintragungen von Benutzern und Lesern diese Bücher zu Unikaten und faszinierenden Zeitzeugnissen werden, die uns einen Einblick in die Welt des Klosters und seiner Umgebung im späten 15. und 16. Jahrhundert geben. Die Klosterbibliothek umfasste ja nicht nur die Literatur, die durch die Mönche selbst erworben wurde, sondern auch Bücher, die Menschen bei ihrem Eintritt ins Kloster mitbrachten oder diesem nach ihrem Tod hinterließen.
Das Jubiläum zum 1.300-jährigen Bestehen des Benediktinerklosters auf der Reichenau im Jahr 2024 bietet der Badischen Landesbibliothek einen guten Anlass, sich diesem spannenden Bibliotheksbestand mit modernen technischen Methoden zu widmen, ihn so einem breiteren Publikum zugänglich zu machen und zugleich neue Forschungsansätze zu ermöglichen.
Das Projekt wird durch die Stiftung Kulturgut Baden-Württemberg gefördert.
Was sind die Ziele des Projekts?
Das Projekt umfasst zwei Bereiche: zum einen die Digitalisierung der Drucke mit Hilfe von speziellen Buchscannern in der Digitalisierungswerkstatt der Badischen Landesbibliothek, zum anderen die automatisierte Texterkennung auf Grundlage der so erzeugten Bilddateien. Geleitet wird es von Herrn Gerrit Heim (Abteilungsleiter Regionalia) und Frau Dr. Annika Stello (Abteilungsleiterin Sammlungen).
Während die Badische Landesbibliothek für die Digitalisierung auf ein bereits eingespieltes Team zurückgreifen kann, steht im Bereich der Texterkennung die Herausforderung im Vordergrund, neue Werkzeuge und Arbeitsabläufe zu erproben – das ist mein Anteil am Projekt. Unser gemeinsames Ziel ist, dass Ende März 2024 zu jeder der über 200 Inkunabeln Reichenauer Provenienz qualitativ hochwertige Scans und vollständig durchsuchbare digitale Texte über die Digitalen Sammlungen der Badischen Landesbibliothek abrufbar sind.
Was ist das Besondere, was sind die Herausforderungen an diesem Textmaterial?
Als Wiegendrucke oder Inkunabeln bezeichnen wir Druckerzeugnisse bis zum Jahr 1500, dies entspricht etwa den ersten fünfzig Jahren des Buchdrucks mit beweglichen Lettern. Da die Druckereien in dieser Zeit noch experimentierten, wie sie die Gestaltungskonventionen handschriftlicher Bücher für das neue Medium weiterentwickeln sollten, waren Strukturelemente wie Titelseiten, typographisch abgesetzte Überschriften und Absätze in der Entwicklung begriffen, farbige Initialen oder Gliederungsmarkierungen wurden noch von Hand in die gedruckten Bücher eingetragen (die sogenannte Rubrizierung).

Die Schlussformel der Legenda Aurea von Jacobus de Voragine illustriert das lateinische Abkürzungssystem. Ausgeschrieben beginnt der letzte Absatz: Historia lambardica explicit. quam iacobus de voragine frater ordinis predicatorum. episcopus ianuensis compilauit. (Es endet die lombardische Geschichte, die Jacobus de Voragine, Bruder des Predigerordens und Bischof von Genua zusammenstellte.) Legenda Aurea. Nürnberg: Anton Koberger 1482. Badische Landesbibliothek, D̄l̄ 81. – zum Digitalisat
Die Werkstätten verwendeten jeweils individuell für sie angefertigte Schrifttypen, wodurch sich im Raum nördlich der Alpen eine große Formenvielfalt der Frakturschriften ergab. Insbesondere in lateinischen Texten wurde auch das komplexe Abkürzungssystem der mittelalterlichen Schreibstuben in den Druck übertragen. Und nicht zuletzt der Umgang mit der Drucktechnik selbst war noch nicht überall perfektioniert: Ungleichmäßig kräftige Druckerschwärze und verrutschte Seiten sind in dieser Zeit keine Seltenheit. Die fehlende Standardisierung im Hinblick auf Schrifttypen und Layout, die für die heutige Zeit ungewöhnlichen Abkürzungszeichen und die schwankende Druckqualität machen es unmöglich, solche Texte mit traditionellen OCR-Programmen (OCR steht für „Optical Character Recognition“, auf Deutsch „optische Zeichenerkennung“; ein Programm wäre z.B. der Abbyy FineReader) transkribieren zu lassen, da diese auf die Regelmäßigkeit moderner Druckerzeugnisse ausgelegt sind. Zugleich verhindert der Umfang unseres Korpus von ca. 70.000 Seiten jedoch eine rein händische Bearbeitung.

Nicht nur die Abkürzungszeichen, auch die unregelmäßige Druckqualität der Inkunabeln machen es unmöglich, eine Texterkennung mit traditionellen OCR-Programmen durchzuführen. Hier zum Beispiel ein schief orientierter Textblock und teils undeutliche Buchstaben in De arte audiendi confessiones (Über die Kunst, die Beichte zu hören) des französischen Theologen Jean Gerson. Seine Schriften sind unter den ehemals Reichenauer Inkunabeln besonders häufig vertreten. De sex aetatibus hominis. Nürnberg: Johann Sensenschmidt / Andreas Frisner um 1478. Badische Landesbibliothek, Dg 46. – zum Digitalisat
Für menschliche Leserinnen und Leser stellt die größte Herausforderung an unserem Textmaterial sicherlich die Sprache dar, da die überwiegende Anzahl der Bücher auf Latein verfasst ist: Als Bildungs- und Wissenschaftssprache prägt das Lateinische die theologischen und juristischen Schriften, die einen Großteil des Bestands der ehemaligen Klosterbibliothek ausmachen. Zudem ermöglichte seine Verwendung eine internationale Vermarktung der Bücher, so ist Venedig noch vor Straßburg und Basel der am häufigsten anzutreffende Druckort in der Reichenauer Sammlung. Bemerkenswerte deutschsprachige Texte sind etwa eine zweibändige Bibel von 1485 (Bd.1 und Bd. 2) oder die Fabeln Aesops. Für mich persönlich sind juristische Texte besonders herausfordernd: Diese sind durch die vielen verwendeten Abkürzungen sehr mühsam zu lesen und mir – mangels Kenntnis der zugrundeliegenden Rechtstexte – oft weitgehend unverständlich.

Das Buch des hochberemten Fabeltichters Esopi mit seinen figuren versammelt unter dem Namen des griechischen Dichters Äsop (6. Jh. v. Chr.) Fabelgeschichten aus ganz unterschiedlichen Quellen. Die dargestellte Fabel vom Löwen und Hirten (auch: Androklus und der Löwe) orientiert sich zum Beispiel an einer Erzählung, die bei Aulus Gellius (2. Jh. n. Chr.) überliefert ist. Buch des hochberemten Fabeltichters Esopi mit seinen figuren. Augsburg: Johann Sconsperger 1491. Badische Landesbibliothek, Pb 2. – zum Digitalisat
Wie wird bei diesem Projekt vorgegangen?
Die Entwicklungen der letzten fünfzehn Jahre im Bereich des maschinellen Lernens (oft auch als Künstliche Intelligenz bezeichnet) haben es möglich gemacht, eine computergestützte Texterkennung des komplexen Materials sinnvoll durchzuführen. Das bedeutet, dass die Texte nicht mehr individuell von Menschen transkribiert, also in ein maschinenlesbares Format „abgeschrieben“ werden, sondern dass diese Aufgabe von Computerprogrammen übernommen wird. Im Gegensatz zu herkömmlichen OCR-Programmen ist diese Software aber lernfähig, kann also anhand von Beispielen trainiert werden und das Erlernte dann auch auf ihr noch unbekanntes Material anwenden. Da wir für unsere Frakturschriften des 15. Jahrhunderts auf keine vorgefertigten Lösungen zurückgreifen können, müssen wir selbst ein Texterkennungssystem durch derartiges Training an unsere spezifischen Bedürfnisse anpassen. Hierfür verwenden wir die Software Transkribus, die aus einem EU-geförderten Forschungsprojekt hervorgegangen ist und seit 2019 durch die READ-COOP-Kooperative weiterentwickelt wird.
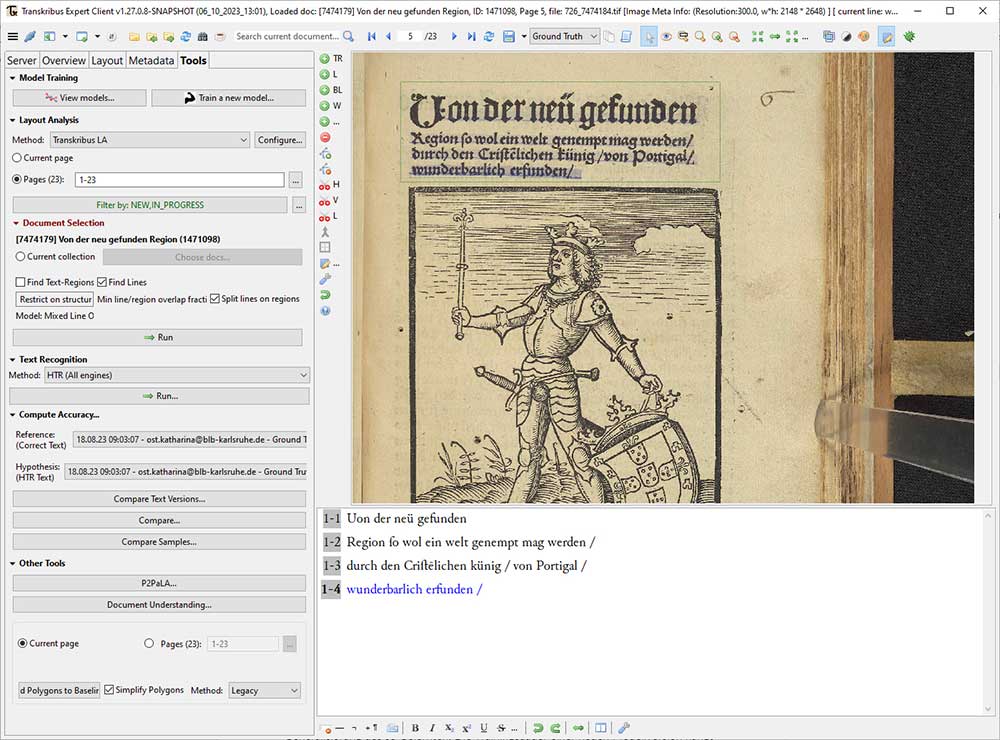
Arbeit an Amerigo Vespuccis Bericht Von der neu gefunden Region die wol ein welt genent mag werden im Transkribus Expert Client. Das Werkzeugmenü links des Digitalisats bietet zahlreiche Optionen für das Modelltraining, zur Analyse des Seitenlayouts sowie zur Texterkennung. Von der neu gefunden Region die wol ein welt genent mag werden. Basel: Michael Furter 1505. Badische Landesbibliothek Dn 401. – zum Digitalisat
Innerhalb dieser Softwareumgebung können wir ein Texterkennungsmodell trainieren, das auf unser spezifisches Material zugeschnitten ist: Wir beginnen mit der Erstellung von händisch korrigierten Transkripten, die als Grundlage für das Training unseres Texterkennungsmodells dienen sollen. Im Rahmen des Trainingsprozesses füttert Transkribus das noch ungenaue Modell zeilenweise mit Bilddaten, vergleicht deren vorgeschlagene Transkription mit ihrem korrigierten Pendant und passt die Modellparameter an, um diese Differenz über mehrere Trainingszyklen immer weiter zu reduzieren. Das so optimierte Modell ist schließlich zur Texterkennung nutzbar.
Der Trainingsprozess gibt dem Modell also keine musterhaften Buchstabenformen vor, sondern es lernt selbst, den für die Texterzeugung signifikanten bildlichen Merkmalen (die also Buchstaben und Wörter voneinander unterscheiden) eine hohe Gewichtung zuzuweisen. Wird das Modell während des Trainings mit einer Vielzahl von Texten und Schrifttypen konfrontiert, erwirbt es auf diese Weise eine gewisse Fähigkeit zur Generalisierung des so Gelernten. Die Trainingsdauer einer neuen Modellversion hängt von der Menge des zur Verfügung gestellten Trainingsmaterials ab und liegt für uns zurzeit bei ca. 30 Stunden.
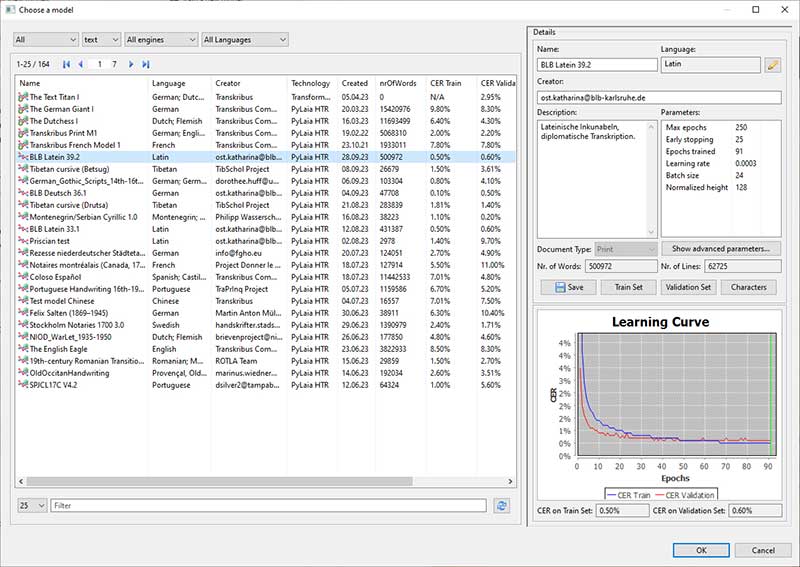
Das fertig trainierte Texterkennungsmodell in der Modellübersicht von Transkribus. Die Learning Curve dokumentiert, wie die Zeichenfehlerrate des Modells (character error rate, CER) im Laufe von 91 Trainingszyklen allmählich gesenkt werden konnte. Während die blaue Kurve zeigt, wie gut das Modell das Trainingsmaterial selbst beherrscht, bildet die rote Kurve seine Leistung auf einer Auswahl unbekannter Textseiten ab.
Mit einem auf diese Weise optimierten Texterkennungsmodell funktioniert die automatische Transkription so gut, dass wir uns ein menschliches Gegenlesen guten Gewissens ersparen können. Meine Arbeit fokussiert sich also auf das Erstellen von zusätzlichem Trainingsmaterial und die manuelle Korrektur komplexer Seitenlayouts (z.B. mehrspaltige Layouts, Diagramme usw.).
Die gewonnenen Volltexte speisen wir anschließend in unsere Digitalen Sammlungen ein, wo sie den Nutzerinnen und Nutzern der BLB Seite an Seite mit den zugehörigen Bilddateien angezeigt und verwendet werden können. Darüber hinaus werden die Digitsalisate und die generierten Volltexte über nationale und internationale Plattformen wie die Deutsche Digitale Bibliothek und Europeana zur Verfügung gestellt.
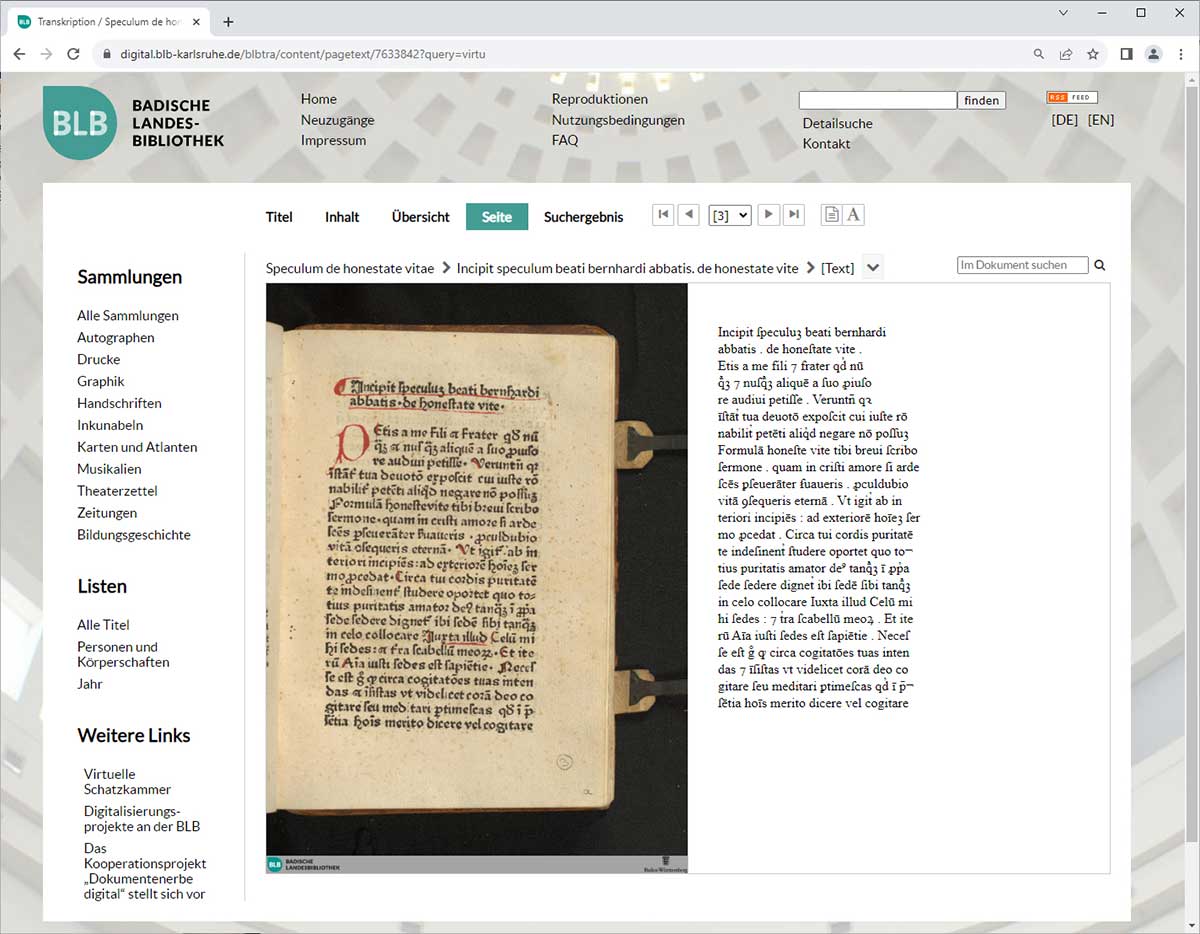
Digitalisat und Volltext des Bernhard von Clairvaux zugeschriebenen Speculum de honestate vitae (Spiegel über die Ehrbarkeit des Lebens) sind in unseren Digitalen Sammlungen Seite an Seite verwendbar. Speculum de honestate vitae. Basel: Martin Flach um 1472-74. Badische Landesbibliothek, Dg 46. – zum Digitalisat
Wie lässt sich mit den Ergebnissen des Projekts weiterarbeiten?
Durch die Integration in die Digitalen Sammlungen ist es möglich, die bereits bearbeiteten Reichenauer Inkunabeln im Volltext zu durchsuchen, z.B. um Informationen zu bestimmten Personen oder Themen zu finden oder um sprachliche Eigenarten der Texte zu untersuchen. Die automatisch erstellten Transkripte können dabei als Hilfestellung dienen, die Frakturschriften der Wiegendrucke zu entziffern, und erlauben es, Textabschnitte unkompliziert in andere Programme zu kopieren.
In Zukunft wird das Vorliegen qualitativ hochwertiger Volltexte es uns ermöglichen, von den aktuellen Innovationen im Bereich der maschinellen Sprachverarbeitung (das sogenannte Natural Language Processing) zu profitieren: Denkbar wäre zum Beispiel, die in den Texten verwendeten Abkürzungen unter Berücksichtigung des jeweiligen Kontexts automatisch auflösen und ausschreiben zu lassen, dass Personen- und Ortsnamen automatisch erkannt und mit Verweisen auf Hintergrundinformationen versehen werden („Named Entity Recognition“), oder auch die automatisierte Erstellung von Übersetzungen und Inhaltszusammenfassungen auf Knopfdruck. Schließlich lässt sich das im Rahmen dieses Projekts trainierte Texterkennungsmodell natürlich auch auf andere Drucke des 15. Jahrhunderts anwenden: Die Reichenauer Sammlung bildet ja nur einen kleinen Teil des Inkunabelbestands der Badischen Landesbibliothek.
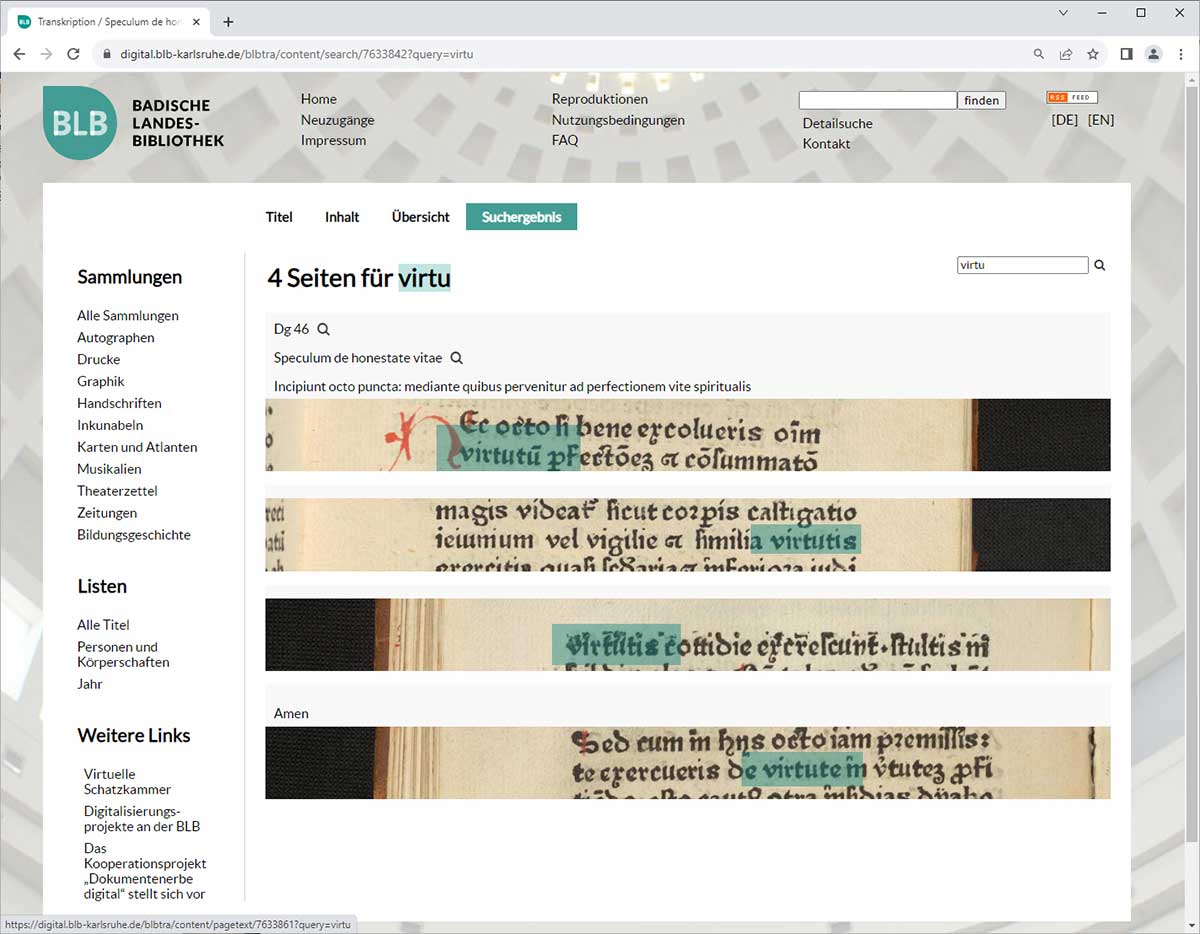
Die Suchfunktion unserer Digitalen Sammlungen verknüpft den Volltext des Speculum de honestate vitae mit den zugehörigen Bildausschnitten. Hier wurde etwa nach dem Auftreten des Begriffes „Tugend“ (lat. virtus) recherchiert. Speculum de honestate vitae. Basel: Martin Flach um 1472-74. Badische Landesbibliothek, Dg 46. – zum Digitalisat
Was war ein erinnerungswürdiges, erkenntnishaltiges Erlebnis während des Projekts?
Mich überrascht immer wieder das vielfältige Nebeneinander des 15. Jahrhunderts: In der Reichenauer Sammlung stehen erste humanistische Texte (etwa von Johannes Reuchlin, Francesco Petrarca und Baptista Mantuanus) neben einem angeblich aristotelischen Traktat über das Handlesen, einem Alexanderroman oder vermeintlichen Augenzeugenberichten des trojanischen Kriegs und der Verurteilung Jesu, um nur einige Beispiele zu nennen.
Neben der Freude am Staunen gibt es aber natürlich auch immer wieder Texte, die einen persönlich auf die eine oder andere Weise berühren: Da ich selbst in Tübingen studiert habe, denke ich hier z.B. an den Druck einer Predigtreihe, die der Pfarrer Martin Plantsch im Jahr 1505 in Tübingen hielt, nachdem dort eine Frau als Hexe verbrannt worden war (Opusculum de sagis maleficis). In seinen Predigten interpretiert Plantsch das Wirken von Dämonen und Hexen als eine von Gott gebilligte Prüfung bzw. Strafe und ruft so die sich von Hexerei bedroht fühlende Gemeinde in die Pflicht, sich zu befragen, auf welche Weise sie selbst dieses Übel verursacht habe. Innerhalb der Reichenauer Inkunabelsammlung wird dieser vergleichsweise mäßigende Text durch zwei Exemplare des berüchtigten „Hexenhammers“ sowie durch Ulrich Molitors De lamiis et phitonicis mulieribus konterkariert, die jeweils für eine strikte Verfolgung von vermeintlichen Hexen und Häretikerinnen plädieren.
Zur Darstellung des Projekts auf der Webseite geht es hier.
Kloster Reichenau. Bibliothek
Digitalisierung
Badische Landesbibliothek